In today’s Hadoop world , MapReduce can be seen as a complement to an RDBMS. MapReduce is a good fit for processes that need to analyse the whole dataset, in a batch operation, specially for ad-hoc analysis. An RDBMS is good for point queries or updates, where the dataset has been indexed to deliver low latency retrieval and update times of a relatively small amount of data. MapReduce suits applications where the data is written once , and read many times, whereas a relational database is good datasets that are continually updated.
Traditional RDBMS MapReduce
Data Size: Gigabytes Petabytes
Access: Interactive and Batch Batch
Updates: Read and write many times Write once , read many times
Structure: Static schema Dynamic schema
Integrity High Low
Scaling Nonlinear Linear
- MapReduce & RDBMS is the amount of structure in the datasets that they operate on. Structured data is the data that is organised into entities that they have a defined format, such as XML documents or database tables that conform to a particular predefined schema. This is the realm of the RDBMS.
- Semi Structured data is looser, and through there may be a schema, is often ignored, so it may be used only as a guide to the structure of the data.
- Unstructured data does not have any particular internal structure, for example, plain text or image data.
- Map Reduce works well on unstructured or semi structured data , since it designed to interpret the data at processing time. In order words , the input keys and values for MapReduce are not an intrinsic property of the data, but they are chosen by the person analyzing the data.
- Relational data is often normalized to retain its integrity & remove redundancy.
- Map Reduce is linearly scalable programming model. Its task is to write Map Function & Reducr function by keeping Shuffle. Each of which defines a mapping from one set of key-value pairs to another. These function are oblivious to the size of the data or the cluster thay are operating on, so they can be used unchanged for small dataset and for massive one.
- Apache Hadoop & Hadoop Ecosystem on Windows Azure Platform(Azure HDInsight):
- Common: A set of operations & interfaces for distributed filesystems & general I/O (Serialization, Java RPC, persistent data structures)
- Avro : A serialization system for efficient , cross language persistent data storage.
- MapReduce: A Distributed data processing model and execution environment thsat runs on large clusters of commodity machines.
- HDFS: A distributed filesystem that runs on large clusters of commodity machines.
- Pig: A data flow language and execution environment for exploring very large datasets. Pig runs on HDFS and MapReduce clusters.
- Hive: A distributed data warehouse. Hive Manages data stored in HDFS & provides batch style computations & ETL by HQL.
- HBase: A distributed , column oriented database, HBase uses HDFS for its underlying storage, supported both batch – style computations using MapReduce and point queries.
- ZooKeeper: A Distributed , highly available coordination service. ZooKeeper provides primitives such as distributed locks can be applied on distributed applications.
- Sqoop: A Tool for efficiently moving data between RDBMS & HDFS (from SQL Server/SQL Azue/Oracle to HDFS and vice-versa)
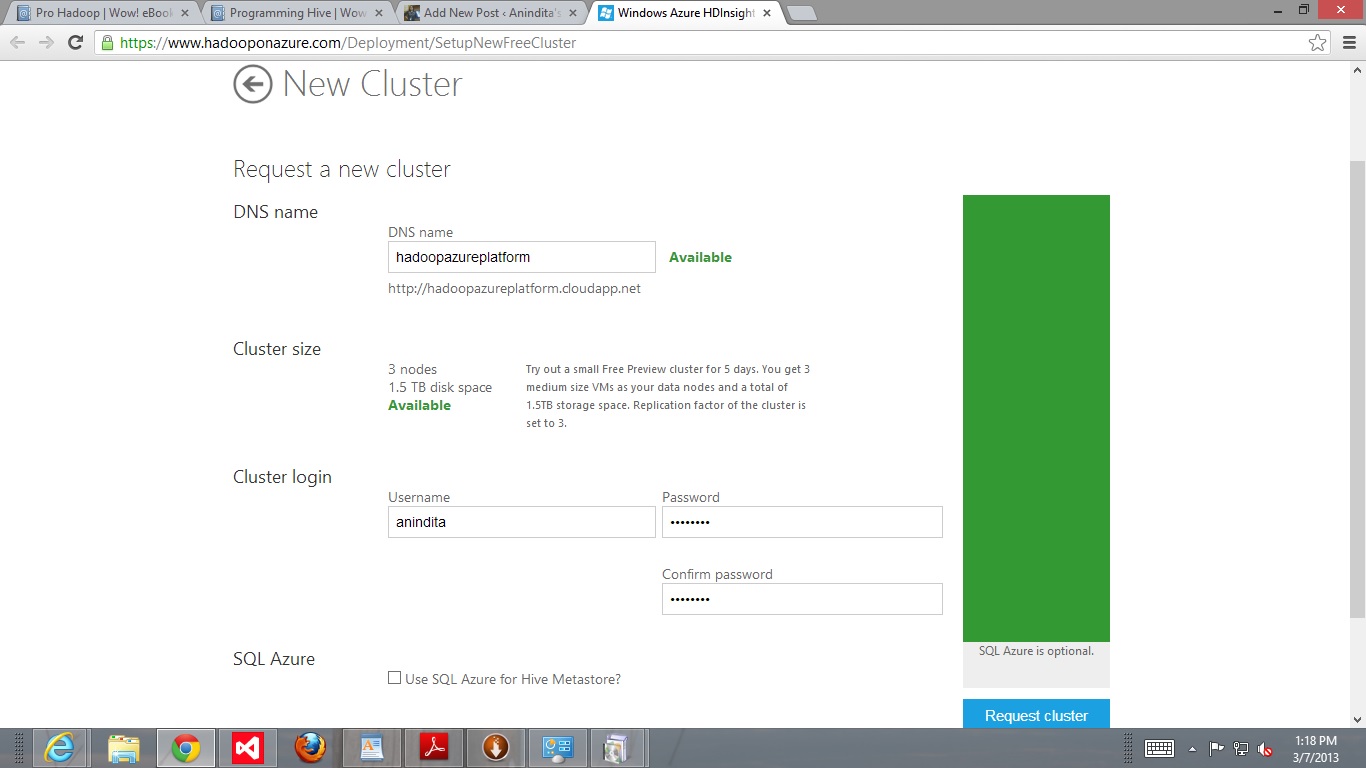
Lets check to create a Hadoop Cluster on Windows Azure HDInsight on http://www.hadooponazure.com:


- Check out the Interactive Console on Hadoop on Azure EMR to execute Pig/Latin scripts or Hive data ware housing queries.

22.569700
88.369698








You must be logged in to post a comment.