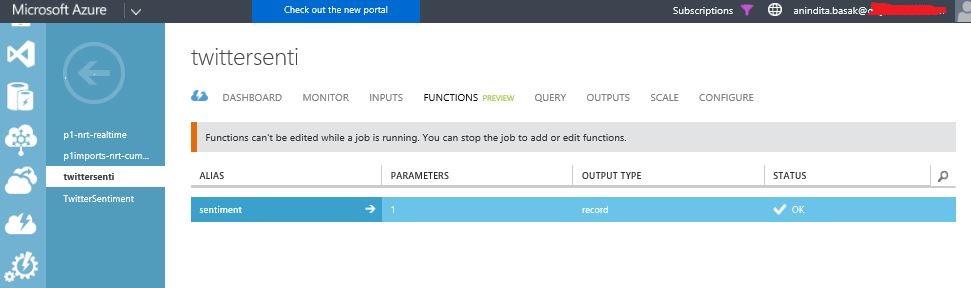
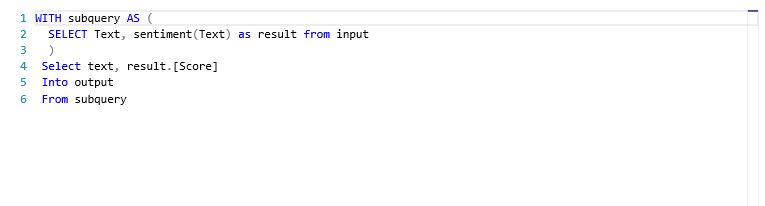
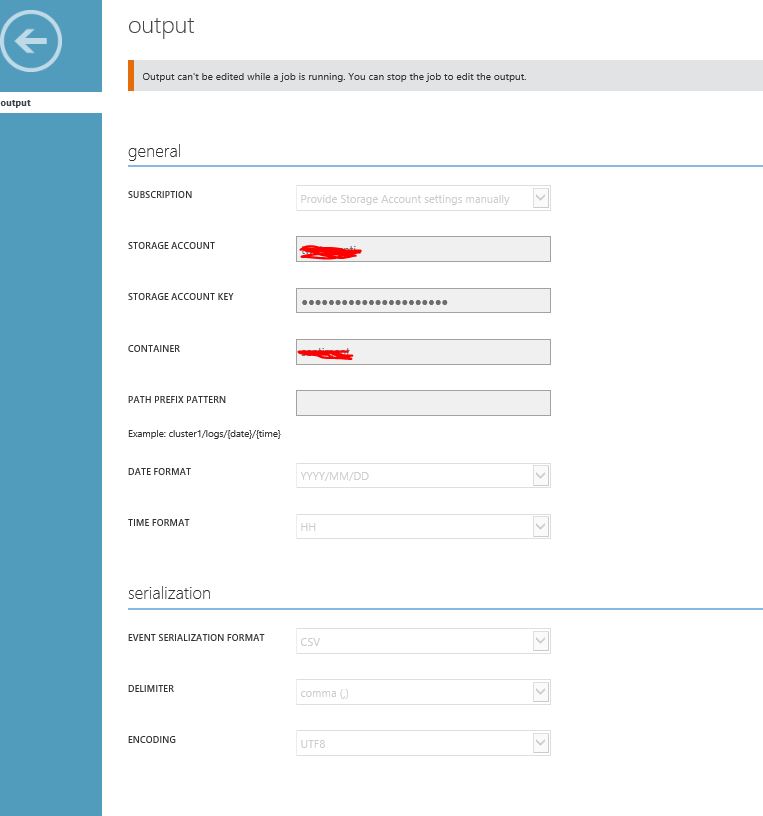
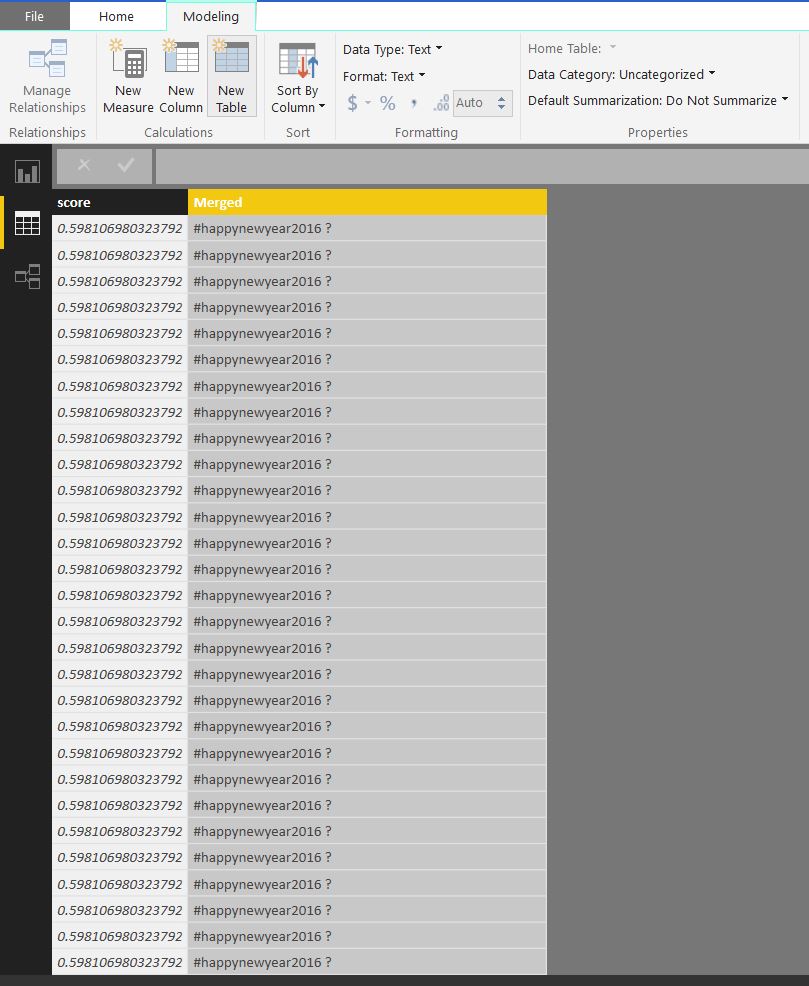
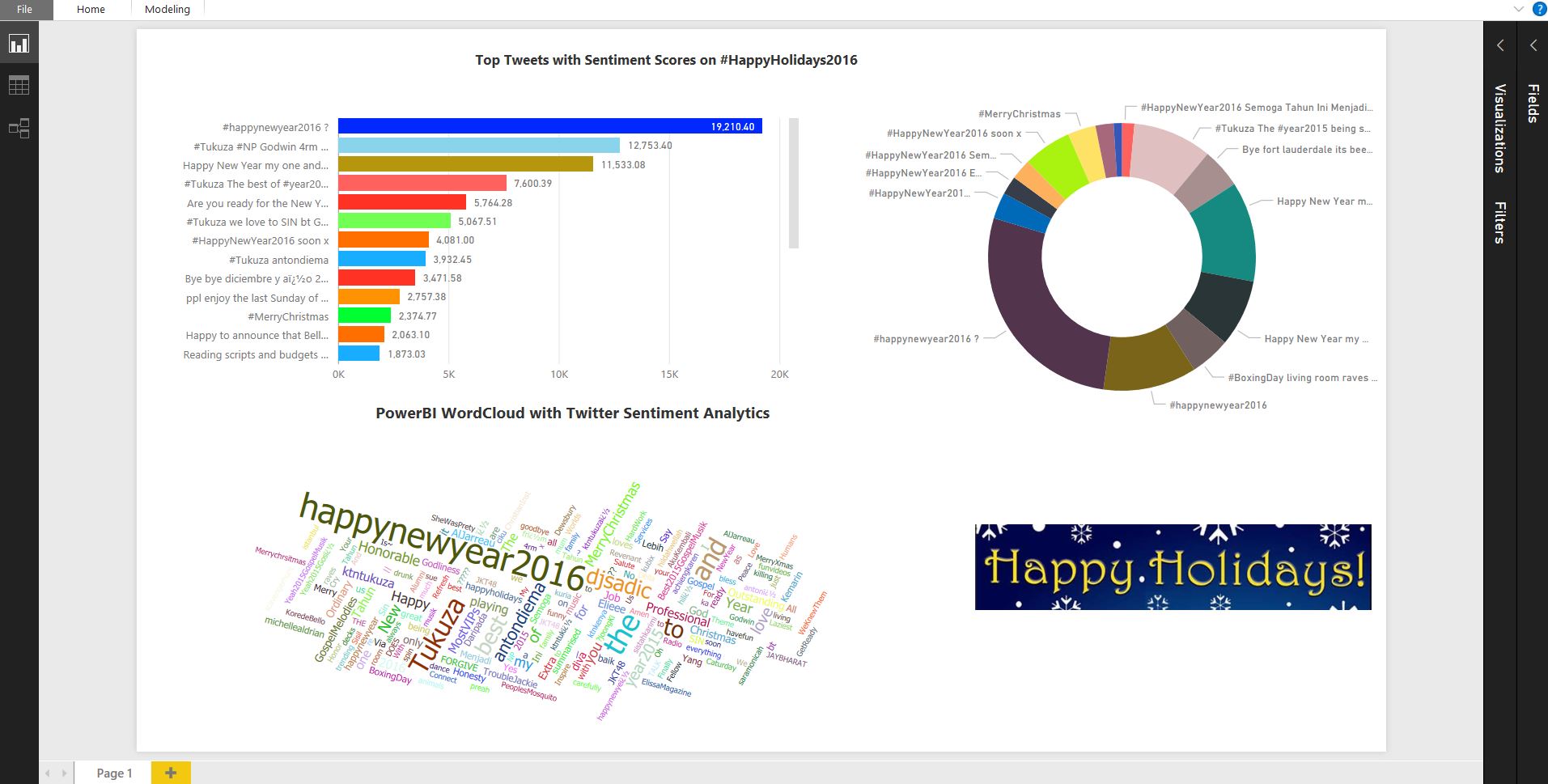
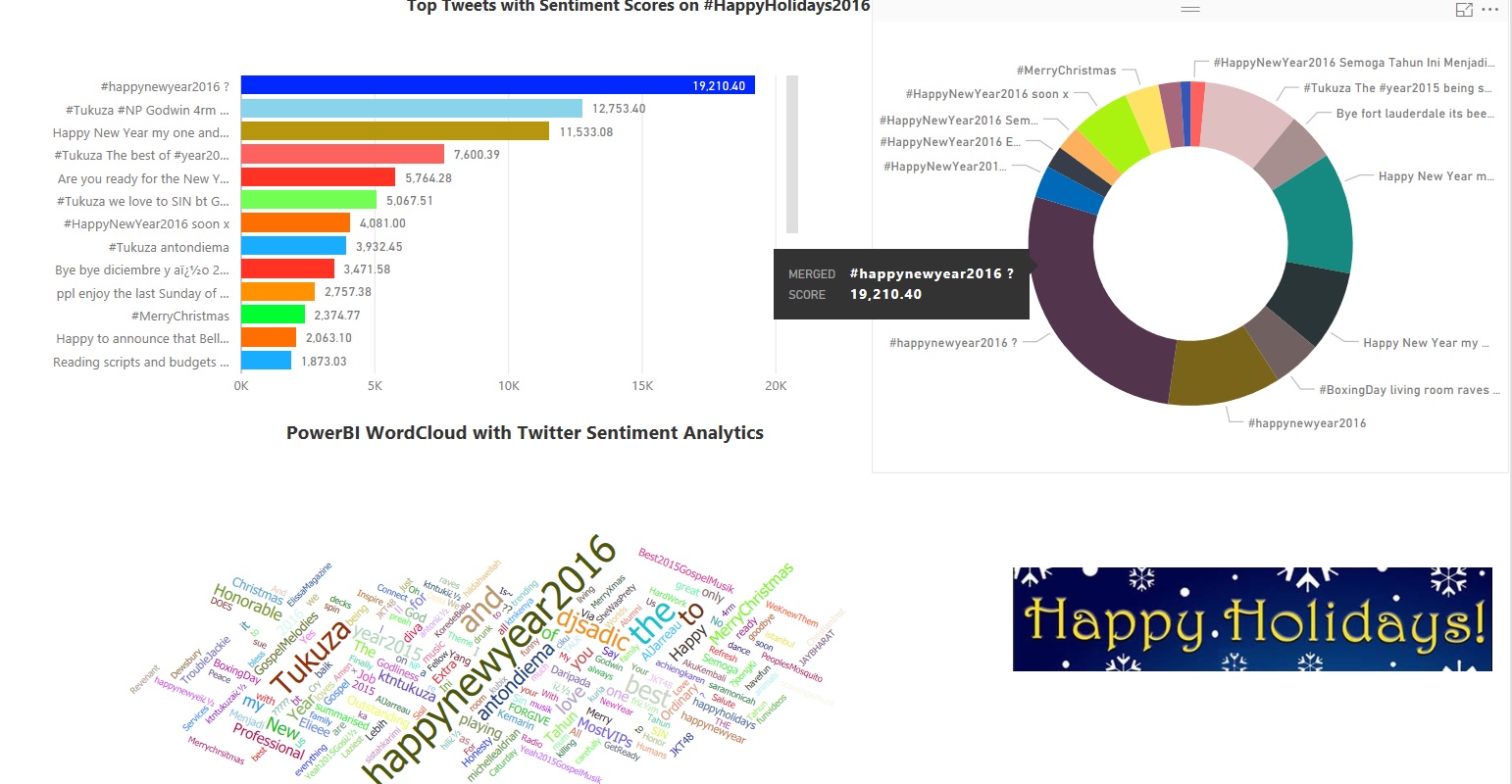
Multicloud Journey- Service comparison of AWS, Azure, GCP
June 21, 2020 Leave a comment

| Service Name | AWS Service | Azure Service | GCP Service | Description |
| Marketplace | AWS Marketplace | Azure Marketplace | GCP Marketplace | Easy-to-deploy and automatically configured third-party applications, including single virtual machine or multiple virtual machine solutions |
| Compute (Virtual Servers) | EC2 instances | Virtual Machines | Compute Engine | Virtual servers allow users ti provision, manage, maintain OS & server software based on Pay-as-you-go/ |
| Compute (Virtual Servers) | AWS Batch | Azure Batch | GCP Batch | Execute large scale parallel & high performance computing applications. |
| Compute (Virtual Servers) | AWS Auto-scaling | Azure VM Scale Sets | GCP Compute Engine Managed Instance Groups | Allows you to automatically scale the number of VM instances, based on defined metrices/thresholds scale out or scale in. |
| Compute (Virtual Servers) | VMWare on AWS | Azure VMWare by CloudSimple | VMware as a service | Redeploy & extend the VMware-based enterprise workloads to Azure by CloudSimple. |
| Compute (Virtual Servers) | Parallel Cluster | CycleCloud | Create, manage , optimize HPC & big compute clusters at scale. | |
| Containers & Container Orchestrators | Elastic Container Service(ECS) AWS Fargate | Azure Container Instances(ACI) | Cloud Run | ACI is the flastest & Simplest way to run containers in Azure. |
| Containers & Container Orchestrators | Elastic Container Registry(ECR) | Azure Container Registry (ACR) | Container Registry Artifact Registry | Allows customers to store Docker formatted images. Used to create all types of container deployments on Azure. |
| Containers & Container Orchestrators | Elastic Kubernetes Service (EKS) | Azure Kubernetes Service (AKS) | Google Kubernetes Engine (GKE) | Deploy orchestrated containerized apps with CNCF Kubernetes at scale. |
| Containers & Container Orchestrators | AWS App Mesh | Azure Service Fabric Mesh | Anthos Service Mesh | Fully managed service that enables developers to deploy microservices applications without managing virtual machines, storage, or networking. |
| Containers & Container Orchestrators | EKS & Kubernetes Container Insights Metrices | Azure Monitor for containers | Kubernetes Engine Monitoring | Azure Monitor for containers is designed to monitor the performance of container workloads deployed to AKS, AKS Engine, ACI, Azure Stack. |
| Serverless (Functions) | AWS Lambda | Azure Functions | Cloud Functions | Provides FaaS (Function as a service) integrating systems & run backend processes in response to events without provisioning compute servers. |
| Database (Relational DB) | RDS | Azure SQL DB Azure Database for MySQL Azure Database for PostgreSQL | Cloud SQL (SQL Server, MySQL, PostgreSQL) | Managed relational database where scale, security, resiliency are handled by the platform |
| NoSQL/Document | DynamoDB SimpleDB Amazon DocumentDB | Azure Cosmos DB | Cloud Spanner | Managed relational db service with dynamic schema, security, scale, maintenance are handled by the cloud platform |
| NoSQL (PaaS) | Azure Cosmos DB | Cloud BigTable Cloud Firestore Firebase Realtime Database | Globally distributed multi-model db which natively supports multiple data-models, key-value, documents, graphs etc. | |
| Caching | AWS ElastiCache | Azure Cache for Redis | Cloud Memorystore Redis Enterprise Cloud | An in-memory based, distributed caching service provides a high performance store typically store used to offload non-transactional work from a database. |
| Database migration | AWS DMS | Azure DMS | Open Source database Migration Tool/SQL Server Database Migration Tool | end to end migration of database migration schema & data from on-premise to cloud platform. |
| Networking Cloud Virtual Networking | AWS VPC | Azure Virtual Network (VNET) | GCP Virtual Private Network (VPC) | Provides an isolated, private environment in the cloud. Users have control over their virtual networking environment, including selection of their own IP address range, adding/updating address ranges, creation of subnets, and configuration of route tables and network gateways. |
| DNS Management | AWS Route 53 | Azure DNS Azure Traffic Manager | Cloud DNS | Managing DNS records using the same credentials & billing and support contracts. |
| Dedicated Network (Hybrid Connectivity) | AWS Direct Connect | Azure ExpressRoute | Cloud Interconnect | Establishes a private network connection from a location to the cloud provider (not over the Internet). |
| Load Balancing | Network Load Balancer | Azure Load Balancer | Network Load Balancing | Azure Load Balancer load-balances traffic at layer 4 (TCP or UDP). |
| Load Balancing in Application layer | Application Load Balancer | Application Gateway Azure Front door Azure Traffic Manager | Global Load Balancing | Application Gateway is a layer 7 load balancer. IT takes backends with any IP that is reachable. It supports SSL termination, cookie-based session affinity, and round robin for load-balancing traffic. |
| Cross-premises connectivity | AWS VPN Gateway | Azure VPN Gateway Azure Virtual WAN | Cloud VPN Gateway | Connects Azure virtual networks to other Azure virtual networks, or customer on-premises networks (site-to-site). Allows end users to connect to Azure services through VPN tunneling (point-to-site). |
| Hybrid Connectivity | AWS Virtual Private Gateway | Azure VNET Gateway | Cloud Router | Enables dynamic routes exchange |
| CDN | AWS CloudFront | Azure CDN | Cloud CDN | A content delivery network (CDN) is a distributed network of servers that can efficiently deliver web content to users. |
| Firewall | AWS WAF | Azure WAF | Cloud Armor | Azure Web Application Firewall (WAF) provides centralized protection of your web applications from common exploits and vulnerabilities. |
| NAT Gateway | AWS NAT Gateway | Azure Virtual Network NAT | Cloud NAT | Virtual Network NAT (network address translation) provides outbound NAT translations for internet connectivity for virtual networks. |
| Private Connectivity to PaaS | AWS Private Link | Azure Private Link | VPC Service controls | Provides private connectivity between VPCs, AWS/Azure/GCP services, on-prem apps, securely on the network |
| Telemetry | VPC Flow Logs | NSG Flow Logs | VPC Flow Logs | Network security group (NSG) flow logs are a feature of Network Watcher that allows you to view information about ingress and egress IP traffic through an NSG. |
| Telemetry Network logs | VPC Flow Logs | NSG Flow Logs | Firewall Rules Logging | NSG logs are feature of Network Watcher that allows you to view info about traffic ingress & egress. |
| Telemetry (Monitoring) | AWS CloudWatch, X-Ray | Azure Monitor | Operations | Comprehensive solution for collecting, analyzing, and acting on telemetry from your cloud and on-premises environments. |
| Network Watcher | AWS CloudWatch | Azure Network Watcher | Network Intelligence Center | Azure Network Watcher provides tools to monitor, diagnose, view metrics, and enable or disable logs for resources in an Azure virtual network. |
| Security & IAM | AWS IAM | Azure AD | Cloud IAM | Allows users to securely control access to services and resources while offering data security and protection. Create and manage users and groups and use permissions to allow and deny access to resources. |
| IAM (Authentication & Authorization) | AWS IAM | Azure RBAC | Cloud IAM | Role-based access control (RBAC) helps you manage who has access to Azure resources, what they can do with those resources, and what areas they have access to |
| Multi-factor Authentication | AWS MFA | Azure AD MFA | GCP MFA | Safeguard access to data and applications while meeting user demand for a simple sign-in process. |
| Auth & Authoriation & Management | AWS Organizations | Azure Management Groups + RBAC | Resource Manager | Structure to organize and manage assets in Azure. |
| AD Domain Services | AWS Directory Service | Azure AD Domain Services | Managed Service for Microsoft Active Directory (AD) | Provides managed domain services such as domain join, group policy, LDAP, and Kerberos/NTLM authentication that are fully compatible with Windows Server Active Directory. |
| Identity managed service | AWS Cognito | Azure AD B2C | Firebase Authentication | A highly available, global, identity management service for consumer-facing applications that scales to hundreds of millions of identities. |
| Management Group | AWS Organizations | Azure Policy Azure Management Groups | Service Account | |
| Encryption | Server side Encryption AWS S3 KMS | Azure Storage Service Encryption | Encryption by default at rest | Azure Storage Service Encryption helps you protect and safeguard your data and meet your organizational security and compliance commitments. |
| Hardware Security Module (HSM) | CloudHSM, KMS | Azure Key Vault | Cloud KMS | Provides security solution and works with other services by providing a way to manage, create, and control encryption keys stored in hardware security modules (HSM). |
| Security | AWS Inspector | Azure Security Center | Security Command Center | Automated Security assessment service provides security & compliance of applications. |
| Web Security with Certificates | AWS Certificate Manager | Azure App Service certificates | Web Security Scanner | |
| Advanced Threat Management | AWS GuardDuty | Azure Advanced Threat Protection | Event Threat Protection | Detect and investigate advanced attacks on-premises and in the cloud. |
| Auditing | AWS Artifact | Service Trust Portal | Provides access to audit reports, compliance guides, and trust documents from across cloud services. | |
| DDoS Protection | AWS Shield | Azure DDos Protection Service | DDoS Security with GCP Armor | Provides cloud services with protection from distributed denial of services (DDoS) attacks. |
| Storage (Object) | AWS S3 | Azure Blob Storage | Cloud Storage | Object storage service, for use cases including cloud applications, content distribution, backup, archiving, disaster recovery, and big data analytics. |
| Storage (VHD) | AWS EBS | Azure Managed Disks | Persistant Disk Local SSD | SSD storage optimized for I/O intensive read/write operations. For use as high-performance Azure virtual machine storage. |
| Storage (File) | AWS EFS | Azure Files, Azure NetApp Files | GCP Filestore | File based storage and hosted NetApp Appliance Storage. |
| Data Archive | S3 Infrequent Access (IA) | Storage cool tier | Nearline | |
| Deep Data Archive | S3 Glacier, Deep Archive | Storage archive access tier | Coldline | Archive storage has the lowest storage cost and higher data retrieval costs compared to hot and cool storage. |
| Data Backup | AWS Backup | Azure Backup | GCP Backup | Back up and recover files and folders from the cloud, and provide offsite protection against data loss. |
| Big Data & Analytics | Redshift | Azure Synapse Analytics (Formerly SQL DW) | GCP BigQuery | Cloud-based Enterprise Data Warehouse (EDW) that uses Massively Parallel Processing (MPP) to quickly run complex queries across petabytes of data. |
| Data warehouse & Lake | Lake Formation | Azure Data Share | Looker | Big data sharing service |
| Big Data Transformations | EMR | Azure Databricks | Cloud DataFlow | Managed Apache Spark-based analytics platform. |
| Big Data Transformations | EMR | HDInsight | GCP Dataproc | Managed Hadoop service. |
| Big Data Transformations | EMR | Azure Data Lake Storage Gen2 | BigQuery | Massively scalable, secure data lake functionality built on Azure Blob Storage. |
| ETL/Data Orchestration | Data Pipeline, Glue | Azure Data Factory | Google Data Fusion | Processes and moves data between different compute and storage services, as well as on-premises data sources at specified intervals. Create, schedule, orchestrate, and manage data pipelines. |
| Enterprise Data discovery | AWS Glue | Azure Data Catalog | Cloud Data Catalog | A fully managed service that serves as a system of registration and system of discovery for enterprise data sources |
| NoSQL db | Dynamo DB | Azure Table Storage, Cosmos DB | Cloud Datastore | NoSQL key-value store for rapid development using massive semi-structured datasets. |
| Visualization & data Streaming | Kinesis Analytics AWS Athena | Azure Stream Analytics ADLA (Data Lake Analytics) ADLS Gen2 | BigQuery | Storage and analysis platforms that create insights from large quantities of data, or data that originates from many sources. |
| Full text searching capability | Cloud Search | Cognitive Search Azure Search | Cloud Search | Delivers full-text search and related search analytics and capabilities. |
| BI tool for Visualization | Quicksight | PowerBI | Datastudio Looker | Business intelligence tools that build visualizations, perform ad hoc analysis, and develop business insights from data. |
| AI Hub | AWS SageMaker | Azure Machine Learning | AI Hub | A cloud service to train, deploy, automate, and manage machine learning models. |
| Bot Capability | Alexa Skills kit | Azure Bot Framework | Dialogflow | Build and connect intelligent bots that interact with your users using text/SMS, Skype, Teams, Slack, Office 365 mail, Twitter, and other popular services. |
| Conversational AI (Speech) | Lex | Speech Services | AI Building blocks- Conversation | API capable of converting speech to text, understanding intent, and converting text back to speech for natural responsiveness. |
| Conversational AI (NLP) | Lex | Azure LUIS | AI Building blocks -Language | A machine learning-based service to build natural language understanding into apps, bots, and IoT devices. Quickly create enterprise-ready, custom models that continuously improve. |
| Conversational AI(Speech to Text & vice versa) | Polly, Transcribe | Speech Services | AI Building blocks – Conversations | Enables both Speech to Text, and Text into Speech capabilities. |
| Enterprise AI (Computer Vision) (Face, Emotions detections) | Rekognition | Azure Cognitive Services | AI Building Blocks – Cloud AutoML AI Building Blocks – Sight | Customize and embed state-of-the-art computer vision for specific domains. Build frictionless customer experiences, optimize manufacturing processes, accelerate digital marketing campaigns-and more. No machine learning expertise is required. |
| Deep Learning | TensorFlow with SageMaker | ONNX ML.NET | TensorFlow | open source and cross-platform machine learning framework for both machine learning & AI |
| Data Science/Deep Learning VM | AWS Deep Learning AMIs | Azure DSVM | Deep Learning VM Image | Pre-Configured environments in the cloud for Data Science and AI Development. |
| Notebooks | AWS SageMaker Notebook instances | Azure Notebooks | AI Platform Notebooks | Develop and run code from anywhere with Jupyter notebooks on Azure. |
| Deep Learning Containers | AWS Deep Learning Containers | GPU Support on AKS | Deep Learning Containers | Graphical processing units (GPUs) are often used for compute-intensive workloads such as graphics and visualization workloads. |
| Automated Data Labeling | Automate Data Labeling with SageMaker | Azure ML – Data Labeling | Data Labeling Service | A central place to create, manage, and monitor labeling projects (public preview). Use it to coordinate data, labels, and team members to efficiently manage labeling tasks |
| ML Platform compute | AWS SageMaker ML Instance Types | Azure ML Compute Targets | AI Platform Training | Designated compute resource/environment where you run your training script or host your service deployment. This location may be your local machine or a cloud-based compute resource |
| ML Service Deployments | SageMaker Hosting Services-Model Deployment | Azure ML – Deployments | AI Platform Predictions | Deploy your machine learning model as a web service in the Azure cloud or to Azure IoT Edge devices |
| Monitor data drift | SageMaker Model Monitor | Azure ML – Data Drift | Continuous Evaluation | Monitor for data drift between the training dataset and inference data of a deployed model |
| TPU | AWS Inferencia | Azure ML – FPGA | Cloud TPU | FPGAs contain an array of programmable logic blocks, and a hierarchy of reconfigurable interconnects. The interconnects allow these blocks to be configured in various ways after manufacturing. |
| ML Ops | MLOps with SageMaker | Azure MLOps | GCP KubeFlow | MLOps, or DevOps for machine learning, enables data science and IT teams to collaborate and increase the pace of model development and deployment via monitoring, validation, and governance of machine learning models. |
| DevOps & App Monitoring | CloudWatch, X-Ray | Azure Monitor | Operations | Maximizes the availability and performance of your applications and services by delivering a comprehensive solution for collecting, analyzing, and acting on telemetry from your cloud and on-premises environments. |
| Code collaborations | Code Build CodeDeploy CodeCommit CodePipeline | Azure DevOps (Azure Board, Azure Pipeline, Azure Build & Release, Azure Repos) | Cloud Source Repositories | A cloud service for collaborating on code development. |
| Automation | OpsWorks | Azure Automations | Cloud Composer | Automation gives you complete control during deployment, operations, and decommissioning of workloads and resources. |
| Automated Infra Provisioning | CloudFormation | Azure Resource Manager VM extensions Azure Automation | Cloud Deployment Manager | Provides a way for users to automate the manual, long-running, error-prone, and frequently repeated IT tasks. |
| CLI, SDK interface | AWS CLI | Azure CLI, PowerShell | PowerShell on GCP GCloud SDK | Built on top of the native REST API across all cloud services, various programming language-specific wrappers provide easier ways to create solutions. |
| Building of Code | AWS CodeBuild | DevOps Build | Cloud Build | Fully managed build service that supports continuous integration and deployment |
| Managed Artifacts Repository | AWS CodeArtifact | Azure DevOps Artifacts | Artifact Registry | Add fully integrated package management to your continuous integration/continuous delivery (CI/CD) pipelines with a single click. |
| IoT Service | AWS IoT | Azure IoT Hub Azure Event Hub | Cloud IoT Core | A cloud gateway for managing bidirectional communication with billions of IoT devices, securely and at scale. |
| IoT data processing | AWS Kinesis Firehose, Kinesis Streams | Azure Event Hubs Azure Stream Analytics HDInsight Kafka | Cloud IoT core Cloud Pub/Sub GCP Dataflow | Process and route streaming data to subsequent processing engine or storage or database platform. |
| IoT on Edge | AWS GreenGrass | Azure IoT Edge | Edge TPU | Deploy cloud intelligence directly on IoT devices to run in on-premises scenarios. |
| IoT Things Graph/Digital Twins | IoT Things Graph | Azure Digital Twins | Device Registry | Create spatial intelligence graphs to model the relationships and interactions between people, places, and devices. Query data from a physical space rather than disparate sensors. |
| Messaging Storage | AWS SQS | Azure Queue Storage | Cloud Pub/Sub | Provides a managed message queueing service for communicating between decoupled application components. |
| Reliable Messaging | SQS | Service Bus Queue | Cloud Pub/Sub | Supports a set of cloud-based, message-oriented middleware technologies including reliable message queuing and durable publish/subscribe messaging |
| Messaging with notification | AWS SNS | Azure Event Grid | Cloud Pub/Sub | A fully managed event routing service that allows for uniform event consumption using a publish/subscribe model. |
| Cloud Management Advisory | Trusted Advisor | Advisor Azure Security Center | GCP Recommender | Provides analysis of cloud resource configuration and security so subscribers can ensure they’re making use of best practices and optimum configurations. |
| Billing API | AWS Usage & Billing Report AWS Budgets | Azure Billing API | Cloud Billing | Services to help generate, monitor, forecast, and share billing data for resource usage by time, organization, or product resources |
| Migrate on-prem workloads | Application Discovery Services | Azure Migrate | Assessment & Migration tool | Assesses on-premises workloads for migration to Azure, performs performance-based sizing, and provides cost estimations. |
| Telemetry Analysis of lift-shoft | EC2 Systems Manager | Azure Monitor | Operations (formerly StackDriver) | Comprehensive solution for collecting, analyzing, and acting on telemetry from your cloud and on-premises environments. |
| Trace | CloudTrail | Azure Monitor | Cloud Trace | Comprehensive solution for collecting, analyzing, and acting on telemetry from your cloud and on-premises environments. |
| Logging & Performance Monitoring | CloudWatch | Azure Application Insights | StackDriver Debugging/Logging | Application Insights, is an extensible Application Performance Management (APM) service for developers and DevOps professionals. |
| Cost Management | AWS Cost explorer | Azure Cost Management | GCP Cost Management | Optimize cloud costs while maximizing cloud potential. |
| Mobile Service | Mobile Hub Mobile SDK Mobile Analytics | Azure Xamarin Apps, App Center | GCP App Engine | Provides backend mobile services for rapid development of mobile solutions, identity management, data synchronization, and storage and notifications across devices. |
| Device Farm | AWS Device Farm | Azure App Center | Firebase Test Lab | Provides services to support testing mobile applications. |
| Bulk Data Transfer | Import/Export Disk, | Azure Import/Export | Transfer appliance | A data transport solution that uses secure disks and appliances to transfer large amounts of data. Also offers data protection during transit. |
| Petabyte to exabyte level data transfer to Cloud | Import/Export Snowball, SnowballEdge, Snowball Mobile | Azure DataBox | Transfer Appliance | Petabyte- to exabyte-scale data transport solution that uses secure data storage devices to transfer large amounts of data to and from Azure |
| Storage Gateway | AWS Storage Gateway | Azure StoreSimple | Google Cloud Storage | Integrates on-premises IT environments with cloud storage. Automates data management and storage, plus supports disaster recovery. |
| Data Sync | AWS Data Sync | Azure File Sync | Cloud Data Transfer | Data sync services |
| Serverless Workflow | AWS SWF | Azure Logic Apps | GCP Composer | Serverless technology for connecting apps, data and devices anywhere, whether on-premises or in the cloud for large ecosystems of SaaS and cloud-based connectors. |
| Hybrid | AWS Outposts | Azure Stack Azure ARC | GCP Anthos | For customers who want to simplify complex and distributed environments across on-premises, edge and multi-cloud |
| Media | AWS Elemental Media Convert Elastic Transcoder | Azure Media Services | GCP Anvato Zync Render Game Servers | Cloud-based media workflow platform to index, package, protect, and stream video at scale. |
| BlockChain | AWS BlockChain | Azure BlockChain Service | Digital Asset | Azure Blockchain Service is a fully managed ledger service that enables users the ability to grow and operate blockchain networks at scale in Azure |
| App Services | AWS ELB (Elastic BeanStalk) | Azure App Service | GCP App Engine | Managed hosting platform providing easy to use services for deploying and scaling web applications and services. |
| API Services | API Gateway | Azure API Management | Apigee API platform, API Analytics | A turnkey solution for publishing APIs to external and internal consumers. |
| Deploy Web apps | LightSail | Azure App Service | Cloud Run, App Engine | Build, deploy, and scale web apps on a fully managed platform. |
| Backend Serverless computation | AWS STEP Function | Azure Logic Apps | App Engine | Connect apps, data and devices on-premises or in the cloud. |
































































You must be logged in to post a comment.