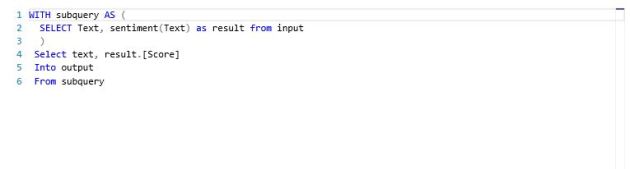
Azure HDInsight 3.1 built on Hortonworks HDP 2.1 consists of lots of important components of hadoop 2.x like highly data-streaming component ‘Apache Tez’, the next generation(ngen) mapreduce 2.0 or ‘YARN’ node on top of HDFS along with realtime data streaming engine ‘Apache Storm’ & distributed message processing framework ‘Apache Kafka’. In this demo, we’ll check a little configuration info on each components running on Azure HDI cluster(3.1).
First, provision a HBase type HDI cluster through Azure PowerShell .

Next, you can check the provisioned Hbase HDI cluster on Azure Portal & enable RDP on it.

Next, On HDI cluster, first check the hadoop-components by browsing the directory ‘C:\apps\dist‘ where , you should see all components of HDP2.1 is prepared except Apache Storm.

Now, Tez -0.4.0.2.1.5.0-2057 is configured itself with HDI 3.1 Hbase cluster so, can check the hadoop-config page to run hive queries with Tez. For that, on cluster desktop, check the Yarn config page which clarifies the Yarn node status.

Now, Similarly, check the tez-site.xml , for configuration level & DAG node status purpose.

Next, jump back to previous directory ‘C:\apps\‘ & write in search-pane on windows explorer ‘Storm‘. Copy the ‘storm-0.9.1.2.1.5.0-2057.zip‘ & paste it into ‘C:\apps\dist\‘ & then unzip it. Under .\bin directory find the Storm.cmd file which is needed for running Storm-Zookeeper, Storm-Nimbus, Storm-Supervisor & UI daemons.
First, configure the Storm.yaml with IPV4 address of HDI cluster then start executing first Storm-zookeeper nodes, master & slave daemon.


Start the Supervisor (Worker) daemon job.

And, at last start the UI job.

Storm-UI can be viewed via web interface through browser on port 8080.

Next, to configure Apache Kafka for distributed message processing, we need to first download the stable version of kafka, I used here Kafka-0.8. You can download it from github repository as .zip https://github.com/apache/kafka
Now, after unzipping it , paste to same directory ‘C:\apps\dist\‘ with other components & start installation of Apache Kafka 0.8 on Azure HDI.
Before to do it, replace the windows .bat files under ‘C:\apps\dist\kafka-0.8\bin\windows\‘ with the latest kafka batch files for windows which can be downloaded from here.
Set the Java ClassPath on Hadoop command line or PowerShell as ‘Set Path=C:\apps\dist\java\bin‘
Next, update the scala & packages through the following commands.
.\sbt.bat update
 & then the list of commands :
& then the list of commands :
.\sbt.bat package
.\sbt.bat assembly-package-dependency
After that, start the Zookeeper-server before starting Kafka-server.
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
 Now, Start the Kafka server by running the following command.
Now, Start the Kafka server by running the following command.
.\bin\windows\kafka-server-start.bat .\config\server.properties
 Next, Create a Topic to post messages using the following command.
.\bin\windows\kafka-create-topic.bat --zookeeper localhost:2181 --replica 1 --partition 1 --topic test
Next, Create a Topic to post messages using the following command.
.\bin\windows\kafka-create-topic.bat --zookeeper localhost:2181 --replica 1 --partition 1 --topic test
 You can check the list of topics by using the following command.
You can check the list of topics by using the following command.
.\bin\windows\kafka-list-topic.bat --zookeeper localhost:2181

On Getting Success message, next start to post message on kafka cluster.Before that , start the console-producer by using the command.
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic test
 Next, start the console-consumer by executing the following command.
Next, start the console-consumer by executing the following command.
.\bin\windows\kafka-console-consumer.bat --zookeeper localhost:2181 --topic test --from-beginning
 The following screenshot displays the demo of running Apache Kafka-0.8 clusters(Producers & Consumers) on Azure Hbase HDI 3.1 cluster.
The following screenshot displays the demo of running Apache Kafka-0.8 clusters(Producers & Consumers) on Azure Hbase HDI 3.1 cluster.





















































































You must be logged in to post a comment.